
진행 기간
2026.01 - 현재
핵심 기술
Next.js 15GraphQLApolloPrismaTailwind CSSFumadocs
진행 기간
2026.01 - 현재
핵심 기술
세상에 하나뿐인 오직 나만의 지식 아카이빙 공간이 있었으면
평소 벨로그나 티스토리 같은 플랫폼을 사용해왔지만, 블로그 기능만으로는 아쉬움이 있었습니다. 단순히 글을 쓰는 곳을 넘어 TIL, 포트폴리오, 그리고 이력서까지 제가 필요한 모든 데이터를 한곳에 모아 관리하고 보여줄 수 있는 '나만의 허브'를 직접 구축하고 싶었습니다.
기존 서비스의 정해진 형식을 따르기보다, 내가 원하는 기능과 디자인을 직접 정의하고 애플리케이션의 전체 구조를 설계하는 데 집중했습니다. 특히 프론트엔드 개발자로서 평소 접하기 어려운 백엔드 로직과 DB 설계를 직접 경험하며, 서비스의 전체적인 흐름을 스스로 제어해보고자 했습니다.
이 사이트는 단순히 정보를 나열하는 곳이 아니라, 제가 마주한 기술적 고민들과 해결 과정들을 꾸준히 쌓아가는 기록소입니다. 기획부터 배포까지 전 과정을 직접 고민하며 구축한 결과물입니다.
효율적인 데이터 흐름과 견고한 인프라를 지향하는 올인원 시스템 설계
단순한 기능 구현을 넘어, 전체 애플리케이션의 지속 가능성과 생산성을 고려한 아키텍처를 설계했습니다. 프론트엔드 전문성을 기반으로 하되, 낯선 백엔드 영역은 AI와 협업하는 '바이브 코딩' 전략으로 해결했습니다. 단순히 코드를 생성하는 것에 그치지 않고, 정확한 요구사항 정의와 전체 시스템 단위의 정합성 검증에 집중했습니다.
GraphQL): Partial Fetching을 통해 필요한 필드만 선택 호출하여 데이터 전송 효율을 극대화했습니다.Server Actions): 별도의 API 엔드포인트 관리 없이 서버에서 직접 데이터를 조작하여 로직의 복잡도를 최소화했습니다.Codegen): typeDefs를 소스로 DB와 FE 타입을 실시간 동기화하여 런타임 에러를 원천 차단했습니다.1. Schema Definition (typeDefs.ts)
import { gql } from 'graphql-tag';
export const typeDefs = gql`
type User {
id: ID!
username: String!
name: String
email: String
image: String
isAdmin: Boolean
posts: [Post!]!
series: [Series!]!
}
type Series {
id: ID!
title: String!
thumbnail: String
posts: [Post!]!
author: User!
authorId: String!
createdAt: String!
updatedAt: String!
}
type Post {
id: ID!
title: String!
thumbnail: String
content: String!
published: Boolean!
viewCount: Int!
readingTime: Int!
author: User!
authorId: String!
tags: [String!]!
series: Series
seriesId: String
seriesOrder: Int
createdAt: String!
}
type Til {
id: ID!
title: String!
content: String!
tags: [String!]!
published: Boolean!
author: User!
authorId: String!
createdAt: String!
}
enum ProjectStatus {
DEVELOPING
LIVE
ARCHIVED
}
type Project {
id: ID!
title: String!
description: String!
thumbnail: String!
techStack: [String!]!
techHighlights: [String!]!
period: String!
githubUrl: String
liveUrl: String
content: String!
status: ProjectStatus!
isFeatured: Boolean!
published: Boolean!
createdAt: String!
}
type Query {
me: User
allPosts: [Post!]!
post(id: ID!): Post
allSeries: [Series!]!
series(id: ID!): Series
allTils(fromDate: String, toDate: String): [Til!]!
til(id: ID!): Til
allProjects(
isFeatured: Boolean
status: ProjectStatus
take: Int
): [Project!]!
project(id: ID!): Project
}
`;2. Codegen Configuration (codegen.ts)
import type { CodegenConfig } from '@graphql-codegen/cli';
const config: CodegenConfig = {
schema: './src/graphql/typeDefs.ts',
documents: ['src/**/*.tsx', 'src/**/*.ts', '!src/generated/**/*'],
generates: {
'src/generated/graphql-resolvers.ts': {
plugins: ['typescript', 'typescript-resolvers'],
config
3. Type-Safe Resolvers (resolvers.ts)
import { ProjectStatus } from '@prisma/client';
import { Resolvers } from '@/generated/graphql-resolvers';
import { prisma } from '@/lib/prisma';
export const resolvers: Resolvers = {
Query: {
me: async (_parent, _args
Docker)
로컬 PC에 직접 DB를 설치하지 않아 시스템이 쾌적하며, 언제든 컨테이너만 내리고 올리면 DB 초기화가 가능합니다.
Vercel)
1인 개발자로서 DB 패치나 커넥션 풀 관리에 드는 시간을 아끼고, 오직 서비스 고도화에만 집중할 수 있는 환경을 만들었습니다.
pnpm db:studio를 통해 실시간으로 확인하며 개발했습니다.정보 전달의 명확성과 운영 효율성을 동시에 확보한 사용자 중심의 인터페이스
화려한 시각적 장치에 매몰되기보다, 콘텐츠의 본질인 '정보 전달'이 가장 원활하게 이루어지는 시스템 설계에 주력했습니다. 독자가 마크다운 형식을 통해 정보를 분명하게 받아드려야함은 물론, 작성자가 코드 레벨에서의 수정 없이도 실제 서비스 화면과 동일한 결과물을 실시간으로 확인하며 포스팅할 수 있는 운영 환경에 초점을 맞췄습니다.
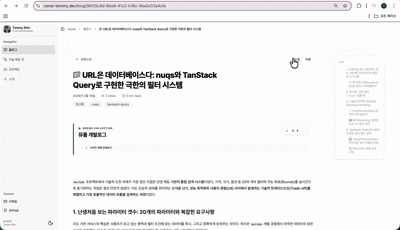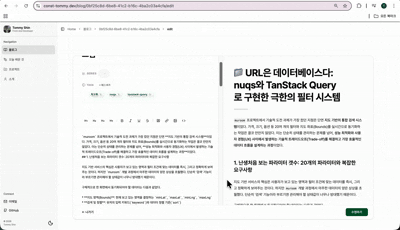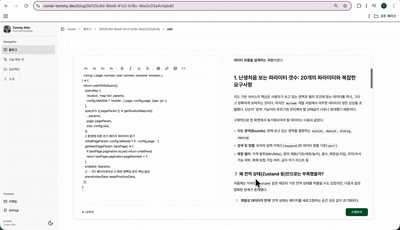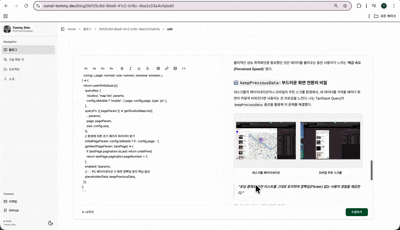
next-mdx-remote: DB 데이터를 서버 사이드에서 안전하게 패칭하여 동적인 포스팅 환경을 제공합니다.fumadocs-ui/core: 전문적인 문서 레이아웃과 컴포넌트를 활용하여 독자의 가독성을 극대화했습니다.rehype-slug를 통해 본문 헤딩을 실시간으로 추출, 긴 글에서도 길을 잃지 않게 돕는 우측 목차(ToC) 기능을 구현했습니다.rehype-slug와 커스텀 헬퍼 함수를 통해 본문의 헤딩을 실시간으로 추출하여 우측 목차를 자동 생성합니다. 이를 통해 사용자는 글의 전체 구조를 한눈에 파악하고, 원하는 지점으로 즉시 이동할 수 있는 최적의 탐색 경험을 얻습니다.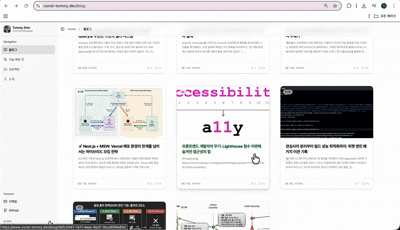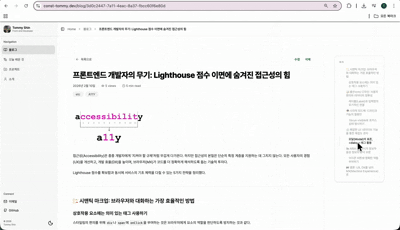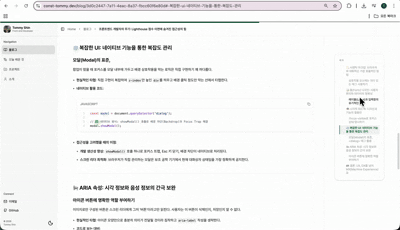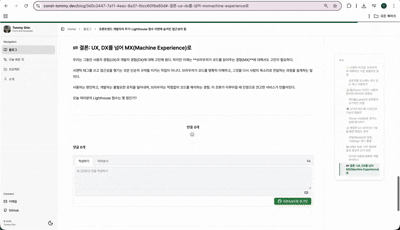
rehype-pretty-code를 연동하여 개발자에게 익숙한 IDE 스타일의 코드 하이라이팅을 제공합니다.ReadProgressBar를 상단에 배치하여 현재 읽기 진행률을 직관적으로 인지할 수 있도록 설계했습니다.shadcn-ui): 시스템 전반에 일관된 톤앤매너를 유지하면서도, 각 콘텐츠 성격에 맞는 유연한 UI 커스터마이징을 수행했습니다.라이브러리의 제약을 넘어서는 구조적 보완과 시스템 통합
정적 도구와 동적 데이터 사이의 간극을 메우기 위해 고민했던 기술적 접합점과 엔지니어링적 대안들을 기록했습니다.
Fumadocs는 강력한 문서 UI를 제공하지만, 기본적으로 로컬 파일 시스템(.mdx)을 직접 읽는 정적 구조로 설계되어 있습니다. 그러나 Vercel(Serverless)과 PostgreSQL(DB) 중심의 운영 환경에서는 런타임에 파일을 생성하거나 프로젝트 폴더 내의 파일을 읽어오는 방식에 물리적 제약이 존재했습니다.
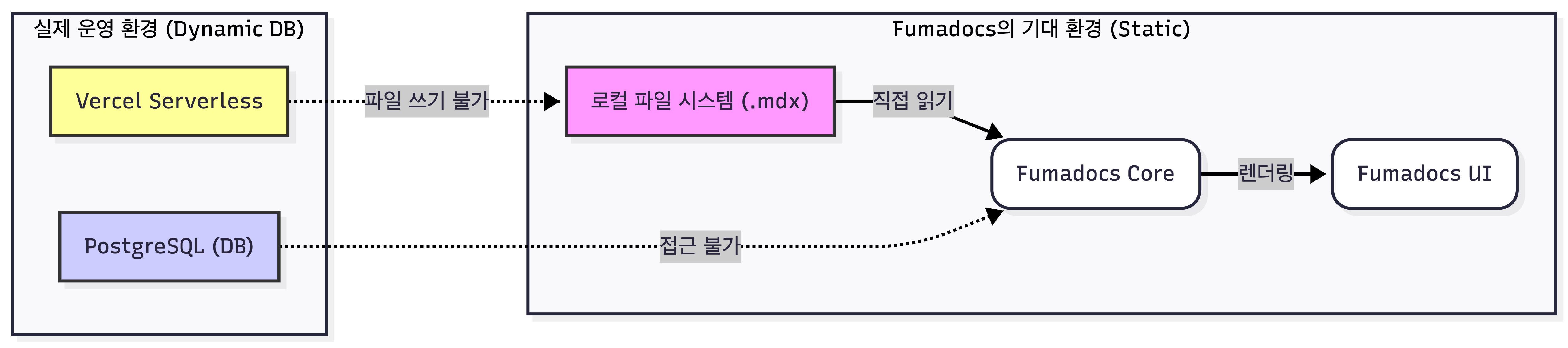
라이브러리의 올인원(All-in-one) 방식을 해체하고, '데이터 페칭'과 'UI 렌더링'의 역할을 분리하여 재조립하는 하이브리드 아키텍처를 설계했습니다.
next-mdx-remote를 활용하여 DB에 저장된 동적 마크다운 데이터를 서버 사이드에서 직접 패칭합니다.Fumadocs의 UI 컴포넌트(getMDXComponents)를 주입하여, 데이터 출처와 관계없이 일관된 문서 UI 경험을 유지했습니다.하이브리드 렌더링 구현부
// 1. Data Layer: DB에서 동적으로 콘텐츠 패칭 (Apollo Client)
const { data } = await getClient().query<GetProjectQuery>({
query: GET_PROJECT,
variables: { id },
context: { fetchOptions: { cache: 'no-store' } },
});
// 2. UI Layer: next-mdx-remote를 통해 렌더링하되 Fumadocs UI 컴포넌트 주입
<article className=
도구가 제시하는 표준 가이드에 갇히지 않고, 서비스의 인프라 특성(Serverless, DB)을 최우선으로 고려하여 아키텍처를 재설계했습니다. 이를 통해 동적 데이터 관리의 유연성과 노션과 같은 전문 문서 사이트의 인터랙티브한 UX라는 두 가지 실익을 모두 확보할 수 있었습니다.
DB에서 실시간으로 불러오는 마크다운은 렌더링 전의 '텍스트' 상태이기에, 기존의 DOM 기반 라이브러리 대신 필요한 제목(Heading) 정보를 골라내는 로직을 직접 작성했습니다.
#이 목차로 오인되지 않도록 정규표현식으로 가볍게 필터링했습니다.github-slugger를 활용해 본문 내 앵커와 목차 링크의 ID를 일치시켜 동적 콘텐츠에서도 정확한 이동이 가능하게 했습니다.export function extractHeadings(content: string): Heading[] {
const slugger = new GithubSlugger();
// 코드 블록 내부의 '#' 노이즈를 먼저 제거
const rawBody = content.replace(/```[\s\S]*?```/g, '');
const headingRegex
모든 요청을 하나의 방식으로 통일하는 편의성보다, 조회(Read)와 수정(Write)의 목적에 따른 실익을 챙기는 데 집중했습니다.
| 구분 | 조회 (Read) | 수정 (Write) |
|---|---|---|
| 선택 기술 | GraphQL (Apollo) | Server Actions |
| 핵심 기여 | 네트워크 비용 최적화 | 데이터 무결성 및 보안 |
| 주요 특징 | 필요한 칼럼만 호출 (Partial Fetching) | 별도 엔드포인트 없는 서버 직접 제어 |
GraphQLServer Actions검색 결과 중 하나가 아닌, 누군가의 시간을 아껴주는 유의미한 인사이트
우리는 매일 구글링이라는 바다에서 답을 찾지만, 때로는 알맹이 없는 포스팅 속에서 시간을 낭비하거나 이미 알고 있던 로직마저 혼선을 빚곤 합니다. 이번 프로젝트는 그런 소모적인 경험을 반복하지 않기 위해, 방문하는 분들에게 실전적인 인사이트를 전달하고 저 또한 지식의 무결성을 검증받는 공간을 만드는 데 초점을 맞췄습니다.
Blog (Insight & Dev Log):
TIL (Continuous Learning):
기술은 끊임없이 변하고 저의 지식 또한 완벽하지 않을 수 있습니다. 이를 보완하기 위해 Giscus를 도입하여 제 GitHub 계정과 연동했습니다.